

Fault detection and diagnostics serve as the foundation of reliable operations. Fault detection identifies when equipment begins showing signs of abnormal behavior, while diagnostics determine the specific cause and location of developing problems. Together, these insights from machine health solutions detect early signs of machine faults that may lead to small defects, line shutdown, or even catastrophic failures.
Continuous asset monitoring tracks how machines are performing in real time and alerts teams when something changes. Diagnostics then identify the likely cause, so teams can address the issue before it worsens or causes unplanned downtime.
This helps teams respond more quickly, keeping production on schedule and minimizing the impact of unexpected stops. Without these insights, small issues can go unnoticed until they cause bigger problems, leading to unplanned downtime, disrupted schedules, and higher repair costs.
Furthermore, every undetected fault costs industrial manufacturers an estimated average $260k per hour of unplanned downtime, according to an Aberdeen Group manufacturing study. The difference between a minor repair and a catastrophic failure often comes down to one critical factor: how early you can detect and isolate equipment faults.
What is Fault Detection and Diagnostics?
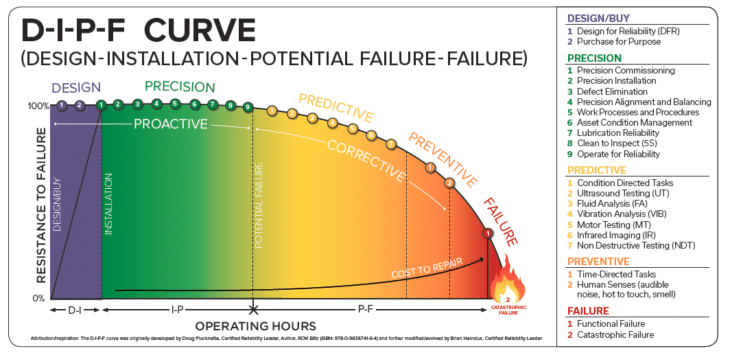
1. Fault Detection: The Search for “Point P”
Fault detection is the systematic process of identifying a deviation from an asset’s normal operating condition before a loss of function occurs. Fault detection compares current behavior against that baseline to spot deviations. In the context of the P-F Curve (Potential Failure to Functional Failure), detection is the act of identifying Point P, the moment a defect becomes detectable, even though the asset is still functioning.
By continuously monitoring parameters—such as vibration, temperature, and ultrasonic signatures—reliability teams can recognize the earliest indicators of mechanical, electrical, or operational degradation. The goal of detection is to identify problems as close to Point P as possible. This then extends the P–F interval, giving maintenance teams more time to plan and execute a controlled intervention before functional failure occurs. The earlier you detect Point P, the more decision time you create. While this stage is critical for fault detection, finding Point P gives you information, though additional steps are required to recognize outcomes.
2. Fault Diagnostics & Localization: Defining the Failure Mode
Fault Diagnostics detect a fault, whereas Fault Localization identifies the exact location of a fault within a system, machine, or component once a general problem has been detected. While detection tells you something is wrong (e.g., abnormal vibration or temperature spike), localization answers where it’s wrong (e.g., the inner race of the drive-end bearing, a specific pump impeller, or a circuit board trace).
This precision eliminates “trial-and-error” troubleshooting, significantly reducing Mean Time to Repair (MTTR) and ensuring that maintenance addresses the specific Failure Mode rather than just the visible symptoms. In turn, this approach can help to reduce downtime and lower maintenance costs.
The Synergy of Fault Detection and Diagnostics
In reliability-centered maintenance (RCM), these two capabilities must work in tandem:
- Detection without Diagnostics results in “blind alarms.” Teams know an asset is distressed but must still perform time-consuming manual inspections to find the cause, often leading to misdiagnosis and wasted labor. Alert fatigue discourages teams and can create mistrust in the approach.
- Diagnostics without Detection is reactive. It means the failure has already progressed to a point where it is obvious, missing the opportunity for low-cost, proactive correction.
The integrated approach of fault detection and diagnostics enables Proactive Asset Management, allowing repairs to be scheduled during planned outages rather than responding to catastrophic emergency failures.
Ready to see how fault detection works?
Watch our Vibration 101 webinar
The Critical Difference: Detection vs. Prediction
Fault detection focuses on the present. It identifies something unexpected or abnormal happening right now. Conversely, predictive maintenance forecasts when a failure might occur by mining historical data for similar conditions or indicators of failure.
Think of it like your car: detection alerts you the moment your brakes start squealing or the check-engine light comes on, while prediction tells you when your brakes will wear out, or your oil will need changing.
Industrial operations require both capabilities, as fault detection provides the real-time awareness that prevents surprises on the production floor, and predictions help to anticipate future occurrences.
Types of Faults Detected
Vibration analysis and ultrasonic monitoring can identify a wide range of mechanical fault conditions, each with distinct signatures and failure progressions. This gives teams clear insights into what’s failing and how it’s progressing. While other diagnostic technologies like oil analysis and electrical fault detection play important roles in comprehensive maintenance programs, this section focuses specifically on faults detectable through vibration and acoustic monitoring techniques.
Mechanical Faults
Bearing wear is one of the most common mechanical faults in rotating machinery, accounting for about 40% of failures, based on research summarized by Academician Qu Liangsheng and reported in a peer‑reviewed study by Hongmei Zheng and Xiaoli Qiao. As bearings deteriorate, they typically show increasing friction and heat along with distinct changes in vibration signatures at characteristic fault frequencies. Additionally, bearing wear can also detect issues in valves, steam traps, and other mechanical systems, creating additional strategies for reliable operations.
Shaft misalignment occurs when rotating equipment shafts fail to maintain proper collinear positioning during power transfer. Misalignment generates excessive radial and axial forces, accelerating wear across the entire drive train and reducing equipment lifespan. According to the U.S. Department of Energy (DOE) Office of Energy Efficiency & Renewable Energy, precision alignment can reduce machinery breakdowns and maintenance costs by up to 50% by mitigating excessive force on bearings and seals.
Even more precisely, phase analysis compares vibration signals at different points on a machine to pinpoint the type and location of a fault, such as determining whether shaft misalignment is angular, parallel, or both.
Rotating asset imbalance develops when the center of mass in rotating components like rotors, fans, or impellers shifts from the geometric centerline. Even small imbalances create destructive centrifugal forces that stress bearings, shafts, and couplings, leading to accelerated wear, higher vibration, and reduced equipment life.
Coupling wear affects power transmission between connected rotating equipment. Deteriorating couplings lose their ability to compensate for minor misalignments, transferring harmful stresses throughout connected systems. Worn couplings pass stress to connected equipment, raising the chance of breakdowns and costly repairs.
Rotating Mechanical looseness occurs when the physical fit between machine components becomes compromised, allowing for excessive movement during operation such as a bearing spinning in its housing. It can be detected through characteristic vibration patterns or by inspecting for play in the affected parts.
Belt/Sprocket wear leads to slip events that reduce power transmission efficiency and lead to heat buildup. Additionally, incorrect belt tension can lead to premature bearing failure through excessively high radial loads or misalignment. Worn belts also introduce vibration patterns that can mask other developing faults.
Operational Faults
Cavitation affects pumps and hydraulic systems when vapor bubbles form and collapse within fluid streams. It causes severe erosion and reduces pump efficiency, leading to higher operating costs, more frequent repairs, and potential unplanned downtime. According to the U.S. Department of Energy, cavitation is a critical failure mode that causes severe erosion damage and can degrade pump efficiency by up to 25% before the unit is replaced. It is characterized by operational instability and is identified in DOE assessment protocols as a primary indicator for system optimization.
Similarly, turbulence is caused by irregular, chaotic fluid motion within a system. It is characterized by rapid changes in pressure and velocity that act as a stressor that leads to physical failure modes in piping and the associated rotating component(s). Turbulence creates fluctuating pressures and forces that stress pipes and rotating components, increasing wear, raising the risk of leaks or failures, and driving up maintenance and repair costs.
Installation/Structural Faults
Structural mechanical looseness occurs when the integrity of a machine’s support system is compromised, allowing the entire unit to shift or “rock” against its foundation. This typically stems from issues like cracked baseplates, loose mounting bolts, or a “soft foot” condition where the machine’s feet do not sit flush against the transition plate. If left unaddressed, structural mechanical looseness can cause a machine to rock on its foundation, increasing vibration, stressing components, and leading to premature failure and costly repairs.
For example, a composite decking manufacturer’s maintenance team kept production running after catching an installation fault within 24 hours of a routine repair. After replacing a lovejoy coupling on a hammer mill, vibration monitoring flagged abnormal levels before the next shift began. A quick inspection confirmed the coupling had shifted out of position after installation. What could have destroyed the part and taken the machine down for hours became a 30-minute fix. The team kept the line running without interruption, and the incident reshaped how they work: technicians now check vibration readings after every repair as standard practice, using post-maintenance data to confirm equipment is running clean before moving on.
A beverage manufacturer’s engineering team had a similar experience with a brand-new gearbox that had just been installed during a scheduled overhaul. Everyone assumed it was fine. Vibration monitoring flagged high readings almost immediately. Investigation revealed the gearbox was defective out of the box, a problem that would have been nearly impossible to prove without continuous data. The team avoided a failure that could have stopped all seven production lines, and used the vibration trend data to hold the OEM accountable for the defective part.
Resonance occurs when an operating frequency matches a structure’s natural frequency, amplifying vibrations to destructive levels. Equipment operating at or near resonant frequencies experiences accelerated wear and the potential for catastrophic failure. Resonance amplifies vibrations, accelerating wear and increasing the risk of catastrophic equipment failure if not detected and managed.
Electrical Faults
Stator Eccentricity (Soft Foot/Distortion) occurs when the stator is no longer perfectly round or is physically distorted (often by a “soft foot” or uneven bolting). This creates an uneven air gap between the rotor and stator, causing a strong magnetic pull force, which, if left unaddressed, can cause rotor vibration, accelerated bearing wear, and premature failure
Broken or Cracked Rotor Bars create “dead spots” in the rotor’s magnetic field. As these spots pass the stator poles while the motor turns, the motor unnaturally “stutters.” Broken rotor bars make the motor run unevenly, which can slow down operations, waste energy, and cause the motor to fail sooner.
Static/Dynamic Air Gap Eccentricity occurs when the rotor is not centered in the stator (static) or is wobbling (dynamic), the magnetic pull varies as the rotor turns, resulting in unwanted forces. The rotor may look aligned visually, but small deviations in the air gap (often fractions of a millimeter) can create significant magnetic forces and cause unplanned downtime and higher repair costs.
Shorted Stator Laminations create “hot spots” that cause the stator to expand unevenly as it warms up. This thermal distortion physically moves the stator closer to the rotor, causing vibration levels to climb significantly as the motor reaches operating temperature. Uneven heating from shorted laminations produces vibration and stress, accelerating wear on the stator, rotor, and bearings, which can reduce motor efficiency and shorten its operational life.
Wondering which faults affect your equipment?
Talk with a rep
Fault Detection Methods
Vibration analysis and ultrasonic monitoring provide the primary detection capabilities for mechanical equipment faults. These methods excel at identifying bearing problems, imbalance, misalignment, and other mechanical conditions that generate characteristic vibration signatures and acoustic patterns. While other technologies like electrical analysis and thermal imaging play important roles in comprehensive monitoring programs, vibration and ultrasonic methods remain the cornerstone technologies for the mechanical faults detection and diagnostics discussed in this guide.
Vibration Analysis – Overall and Fault-Specific Trending
Vibration monitoring remains the backbone of mechanical fault detection. Industry data from the Vibration Institute and ISO 18436 training standards demonstrate that vibration analysis can detect the vast majority (routinely estimated at 85-90%) of mechanical faults in rotating equipment during the ‘potential failure’ stage.
Accelerometers can capture equipment vibration signatures across multiple frequency ranges and intentionally selected “bands of interest” in the trends, such as those demonstrated in Technical Associates’ “Proven Method”. Advanced analysis techniques extract fault-specific frequencies, amplitude trends, and pattern changes that indicate developing problems. Capturing and analyzing vibration signatures allow teams to identify developing equipment problems early, giving them time to plan maintenance, reduce stress on components, and avoid costly repairs.
Ultrasonic Monitoring – Overall and Fault-Specific Trending
Ultrasonic detection captures high-frequency sounds generated by friction, impacts, and turbulence within equipment. This technology excels at detecting bearing lubrication issues, impacting issues, steam leaks, electrical arcing, and compressed air leaks before they become visible or audible to maintenance personnel.
Ultrasonic monitoring provides early warning for lubrication-related problems (the earliest detection method on the P-F curve), often detecting bearing distress 6-8 weeks before vibration analysis shows clear fault signatures, particularly for lower-speed machine components.
Magnetic Flux Density Analysis
Magnetic flux monitoring non-invasively detects changes in electromagnetic fields around motors. This data can also be used to determine the turning speed of the motor. This technique aids in identifying electrical faults such as broken rotor bars, stator winding problems, and air gap variations with frequency-specific trending over time.
These internal imbalances often manifest as electrical inefficiencies due to competing forces; for instance, according to the Department of Energy, electrical faults (specifically voltage unbalance) can reduce motor efficiency by 3–5% while causing a 25% increase in operating temperature. This accelerated thermal stress often leads to premature insulation failure, making early detection vital for both energy savings and equipment reliability.
Temperature Monitoring
Thermal monitoring uses infrared sensors, thermocouples, or similar devices to track equipment operating temperatures. Elevated temperatures often indicate friction, electrical resistance, cooling system issues, or process inefficiencies that precede equipment failure.
Temperature trending reveals gradual degradation patterns, while thermal imaging identifies hot spots that signal immediate attention requirements.
Ready to go further?
Explore the Vibration 101 Webinar Series
Diagnostic Techniques
Once fault detection systems identify abnormal conditions, isolation techniques determine the specific component, system, or process causing the problem. Effective isolation minimizes troubleshooting time and ensures repairs address root causes rather than symptoms.
Vibration Analysis: Fault-Specific Tools
Time-domain analysis reveals impact events and transient conditions such as cracked gear teeth and bearing impacts. The timewaveform can be listened to as an audio file to provide even greater context to the analyst. Frequency-domain analysis isolates specific fault frequencies related to bearing defects, imbalance, or misalignment as described in the ‘Mechanical Faults’.
Ultrasonic Analysis: Fault-Specific Tools
Ultrasonic Monitoring capabilities can vary significantly depending on the sensor being used to collect the ultrasonic data. For Augury’s Ultrasonic instrumentation, high frequency data is captured with full spectral capabilities for both time-domain and spectral analysis that can be analyzed similarly to as described in this section for vibration analysis. This allows high diagnostic accuracy on machines that are operating at speeds lower than traditional vibration analysis can effectively detect.
Magnetic Flux Density Analysis: Fault-Specific Tools
Similarly, magnetic spectral and timewaveform tools can be used to determine changes in the magnetic field of the motor over time that are commonly linked to motor-specific issues. Using a combination of magnetic flux density data to detect a shift in the magnetic field at specific frequencies, alongside vibration, and temperature data provides a multi-tiered approach to better electrical fault analysis that are not as reliably detected when compared to mechanical faults by using any of these technologies by itself.
Phase Analysis: Diagnostic and Localization Tool
As a Diagnostic Tool
Phase analysis diagnostics is a method used in vibration testing to see how different parts of a machine move in relation to each other. It looks at the timing, or phase, of vibrations compared to a reference point, usually tied to the machine’s rotation. By doing this, it can help spot problems like misalignment, imbalance, or loose components before they turn into bigger issues.
As a Localization Tool
Phase Analysis examines the timed relationship between two or more measurement points. When multiple sensors detect abnormal energy levels, phase determines the specific component or connection point generating the fault signature and how it is behaving in relationship to the other components. This eliminates the “trial-and-error” approach to maintenance by providing signal-level proof of the fault’s source.
Go deeper on Phase Analysis
Download the Technical Guide
Asset Types and Common Fault Patterns
Different equipment types exhibit characteristic fault patterns and require tailored detection approaches. Understanding these asset-specific vulnerabilities helps maintenance teams implement appropriate monitoring strategies and prioritize protective measures.
Critical Rotating Equipment
Motors, pumps, fans, and compressors represent the backbone of most industrial operations. These assets typically operate continuously under varying load conditions, making them susceptible to gradual wear patterns and sudden operational changes.
Most susceptible faults: Bearing wear, imbalance, and misalignment dominate failure modes in critical rotating equipment. The Electric Power Research Institute (EPRI) identifies bearing problems as responsible for 40-50% of motor failures, while imbalance and misalignment account for an additional 25-30%.
Detection priority: Critical rotating assets require continuous monitoring due to their high failure impact and relatively predictable degradation patterns. Moreover, early detection systems can identify developing problems 60-90 days before failure, providing ample time for planned maintenance interventions.
Monitoring strategies: Multi-point vibration monitoring, temperature trending, and motor current signature analysis provide comprehensive coverage for critical rotating equipment. Phase Analysis adds precision for complex fault isolation in high-value assets.
Gearboxes and Power Transmission
Gearboxes, couplings, and drive trains transfer power between prime movers and driven equipment. These mechanical interfaces experience concentrated stresses that accelerate wear under poor operating conditions.
Most susceptible faults: Gear mesh and teeth problems, coupling deterioration, and belt wear represent primary failure modes. Misalignment between connected equipment multiplies these problems by creating uneven load distribution across power transmission components.
Criticality in production lines: Power transmission failures often affect multiple downstream processes, magnifying their operational impact beyond the immediate equipment failure. A single gearbox failure can shut down entire production lines until repairs are completed.
Detection approaches: Gear mesh monitoring through vibration analysis, oil analysis for wear debris detection, and thermal monitoring for efficiency assessment provide comprehensive gearbox protection. Coupling monitoring focuses on alignment verification and wear trending.
Hydraulic and Pneumatic Systems
Hydraulic pumps, gear pumps, and pneumatic compressors provide power transmission through fluid media. These systems operate under high pressures that can cause rapid failure progression once problems develop.
Most susceptible faults: Cavitation, pressure instability, and seal degradation represent primary concerns. Cavitation can destroy pump components within days once it becomes severe, while pressure instabilities indicate control system problems that affect process quality.
Impact on process control: Fluid power systems often provide critical process control functions where performance degradation directly affects product quality, safety systems, or environmental controls.
Monitoring considerations: Pressure monitoring, flow analysis, fluid quality assessment, and cavitation detection provide essential protection for fluid power systems. Ultrasonic monitoring excels at detecting cavitation and internal leakage before they become operationally significant.
Heat Transfer Equipment
Heat exchangers, cooling towers, and boilers manage thermal energy in industrial processes. These assets experience fouling, scaling, and thermal cycling that gradually degrade performance and efficiency.
Most susceptible faults: Fouling accumulation, tube bundle degradation, and efficiency loss represent primary concerns. Heat transfer efficiency directly impacts energy consumption and process capacity.
Thermal performance and energy impact: Heat transfer equipment degradation, primarily through fouling and scale accumulation, creates a significant thermal barrier that increases energy consumption while simultaneously reducing process capacity. According to the U.S. Department of Energy (DOE), even minor fouling, such as 1/32 of an inch of scale, can increase fuel consumption by 2%, while severe conditions in boilers and heat exchangers can drive energy costs up by as much as 40%. Proactive monitoring of heat transfer efficiency is critical for maintaining throughput and minimizing the carbon footprint of industrial operations.
Detection strategies: Thermal monitoring, pressure drop analysis, and efficiency trending provide early indicators of heat transfer degradation. Vibration monitoring detects mechanical problems in fans, pumps, and other rotating components within heat transfer systems.
Process-Critical Assets
Agitators, mixers, and conveyors provide material handling and processing functions unique to specific industries. These assets often operate in harsh environments with contamination, corrosion, and process variability.
Most susceptible faults: Fault patterns vary significantly by application and operating environment. Agitators experience bearing problems and shaft fatigue, while conveyors face belt wear and drive system issues. Custom monitoring approaches: Process-critical assets often require application-specific monitoring strategies that account for unique operating conditions, environmental factors, and process interactions.
Solution Architecture: How Modern Systems Work
Contemporary fault detection and isolation systems integrate multiple technologies into unified platforms that provide comprehensive equipment protection. These systems combine real-time monitoring, advanced analytics, and predictive algorithms to deliver actionable insights for maintenance teams.
Technology Overview
Real-time monitoring capabilities form the foundation of modern fault detection systems. Continuous sensor networks collect vibration, temperature, pressure, and acoustic data at sampling rates sufficient to capture transient events and gradual degradation trends.
Advanced sensor technologies now offer wireless connectivity, edge processing, and battery life measured in years rather than months. These improvements eliminate installation barriers that previously limited monitoring coverage to only the most critical assets.
Data collection and processing systems handle the massive volumes of data generated by comprehensive sensor networks. Cloud-based architectures provide scalable processing capacity while edge computing devices perform real-time analysis for immediate fault detection.
Consequently, modern systems process thousands of data points per second across hundreds of monitored assets, extracting meaningful patterns from complex multi-channel data streams without overwhelming maintenance teams with false alarms.
AI and machine learning pattern recognition continuously improve fault detection accuracy by learning from operational history and outcome data. These algorithms adapt to specific operating conditions, environmental factors, and equipment configurations that affect fault signatures.
Research on industrial AI applications indicates that machine learning systems significantly outperform traditional threshold-based methods, achieving classification accuracies as high as 95.6% compared to the 86.3% typical of legacy approaches. Furthermore, advanced AI models have demonstrated the ability to reduce false alarm rates by more than 60%, providing a more reliable foundation for high-stakes industrial automation.
Prescriptive diagnostics translate fault detection information into specific maintenance recommendations. Rather than simply alerting teams that something is abnormal, prescriptive systems identify the specific component requiring attention and suggest appropriate corrective actions.
System Integration
Modern fault detection systems integrate seamlessly with existing maintenance management infrastructure to provide unified workflow management and data visibility.
CMMS Integration enables automatic work order generation when fault detection systems identify equipment problems requiring maintenance attention. This integration eliminates manual data transfer and ensures maintenance teams receive timely notification of developing issues.
Integration with computerized maintenance management systems also provides access to historical maintenance records, parts inventory data, and technician scheduling information needed to plan appropriate responses to detected faults.
EAM Systems (Enterprise Asset Management) receive fault detection data to support strategic asset management decisions. EAM integration enables maintenance organizations to track asset reliability trends, optimize replacement timing, and justify capital investments based on actual equipment condition data.
ERP Systems (Enterprise Resource Planning) integration ensures fault detection information reaches decision-makers responsible for production planning, inventory management, and financial planning. This visibility enables organizations to adjust production schedules, expedite parts procurement, and allocate maintenance resources based on actual equipment risks.
Data flow and interoperability standards ensure fault detection systems communicate effectively with diverse industrial automation platforms. Modern systems support OPC UA, MQTT, and other industrial communication protocols to integrate with programmable logic controllers, distributed control systems, and existing sensor networks.
Phase Analysis as Advanced Capability
Phase Analysis represents a significant advancement in fault detection and isolation capability, providing signal-level proof of equipment conditions through sophisticated waveform analysis techniques.
Technical advantages over basic monitoring include the ability to isolate fault signatures in noisy environments, differentiate between multiple concurrent fault conditions, and provide quantitative assessment of fault severity and progression rates.
Traditional vibration monitoring tracks amplitude changes in specific frequency bands, but Phase Analysis examines the time-based relationships between measurement points to extract fault information that amplitude-only analysis might miss.
Differentiating capabilities include detection of loose bolts, coupling problems, and foundation issues that generate complex vibration patterns difficult to isolate with conventional techniques. Phase Analysis also provides superior performance in applications where external vibration sources could mask equipment fault signatures.Integration with existing systems allows Phase Analysis to enhance rather than replace existing monitoring infrastructure. The technology works with standard accelerometers and data acquisition systems while providing advanced analysis capabilities through software-based processing algorithms.

Business Value and ROI
Effective fault detection and isolation systems deliver measurable financial returns through reduced maintenance costs, improved equipment reliability, and optimized asset utilization. Understanding these value drivers helps maintenance organizations justify investments and measure program success.
Quantified Benefits
Cost of undetected faults extends far beyond immediate repair expenses. According to benchmarks from the U.S. General Services Administration (GSA) and the Department of Energy, unplanned failures typically cost 3 to 5 times more than equivalent planned interventions. This escalation is driven by emergency labor rates, expedited parts procurement, and secondary damage from failure events.
Research from the National Institute of Standards and Technology (NIST) reveals that organizations transitioning from reactive to data-driven maintenance strategies can reduce equipment downtime by up to 50%. By implementing comprehensive fault detection and predictive monitoring, manufacturers realize an average 15% reduction in direct maintenance costs and a significant increase in total factor productivity. These improvements effectively lower the total cost of ownership (TCO) for critical rotating equipment by mitigating the $119 billion in annual losses attributed to inadequate maintenance infrastructure.
At Canfor’s Grande Prairie mill in northern Alberta, downtime costs more than $100 per minute, and a 57% U.S. tariff on Canadian lumber leaves almost no room for error. Plant Maintenance Superintendent Rick Rombs and his team made equipment reviews a daily discipline, spending 90 minutes every morning working through alerts and catching developing problems weeks before they could escalate. The results are concrete: $1.1M in costs avoided and 59 hours of downtime prevented. As Rick puts it, “Uptime is everything. When you’re running, you’re making money. That’s the number we’re all judged on.”
Downtime reduction metrics demonstrate the operational value of early fault detection. Organizations adopting advanced fault detection and predictive monitoring systems report significant reductions in unplanned downtime compared with reactive maintenance approaches.
Industry research highlights the financial impact of unplanned downtime: according to MaintainX’s 2024 State of Industrial Maintenance report, the average cost of one hour of unplanned downtime is around $25,000 and can exceed $500,000 an hour for larger organizations, depending on industry and facility scale. Certain high-mix, product-sensitive operations, such as food processing, face especially severe impacts due to product spoilage and the cost of cleaning and recovery during stoppages.
Productivity gains result from improved equipment availability, reduced emergency maintenance interruptions, and optimized maintenance scheduling. When maintenance teams can plan interventions based on actual equipment condition rather than reacting to failures, they complete work more efficiently with proper preparation, appropriate parts availability, and optimal working conditions. This shift enables organizations to maximize productive operating time while minimizing maintenance-related production disruptions.
Operational Impact
Labor productivity improvements enable maintenance teams to focus on value-added activities rather than emergency response. Planned maintenance typically requires 50-70% less labor time compared to emergency repairs due to better preparation, parts availability, and optimal working conditions.
Deloitte’s manufacturing research indicates that maintenance organizations using advanced fault detection systems complete up to 20% more planned maintenance work compared to reactive approaches, improving overall maintenance efficiency and equipment reliability.
Therefore, maintenance efficiency gains result from targeted interventions based on actual equipment condition rather than fixed time intervals. Condition-based maintenance reduces unnecessary preventive actions while ensuring critical repairs occur before failures impact operations.
The U.S. Department of Energy (DOE) reports that predictive maintenance approaches save approximately 8% to 12% over regularly scheduled preventive maintenance alone, while improving equipment availability and increasing production from 20% to 25%.
Asset life extension occurs when fault detection systems enable maintenance teams to address problems before they cause permanent equipment damage. Early intervention prevents cascading failures that often require major repairs or complete asset replacement.
Safety improvements result from reduced emergency maintenance situations and better advance warning of potentially hazardous equipment conditions. Research from the European Agency for Safety and Health at Work identifies maintenance activities as responsible for 15-20% of workplace injuries. Similarly, industrial data cited by the Society for Maintenance & Reliability Professionals (SMRP) reveals that accidents are 5 times more likely during breakdown work than during planned and scheduled maintenance.
Strategic Value
The shift from reactive to predictive maintenance transforms maintenance organizations from cost centers responding to problems into strategic contributors supporting business objectives. This transformation requires cultural change but delivers sustainable competitive advantages.
Positioning maintenance teams as strategic professionals rather than reactive firefighters improves job satisfaction, retention, and organizational effectiveness. Maintenance professionals report higher job satisfaction when their work focuses on preventing problems rather than responding to emergencies.
Advanced fault detection systems support this transformation by providing maintenance teams with actionable information that enables proactive decision-making. Teams equipped with reliable fault detection tools can plan work efficiently, communicate effectively with operations, and demonstrate measurable value to organizational leadership.
Calculate your potential savings
Use our ROI calculator
Third-party proof beats vendor promises
Read the study
Implementation Roadmap
Successful fault detection and diagnostic implementation requires systematic planning, phased deployment, and continuous improvement based on operational experience. Organizations achieve best results through structured approaches that build capabilities progressively.
Starting with Pilot Programs
Asset selection criteria for initial deployment should prioritize high-value equipment with predictable fault patterns and clear business impact. Ideal pilot assets include critical rotating equipment with documented failure history and significant downtime costs.
Selecting approximately 20 representative assets for pilot programs demonstrates value while maintaining a manageable scope and complexity. Pilot assets should represent typical operating conditions while providing clear success metrics.
Baseline establishment requires documenting current maintenance costs, failure rates, and downtime patterns before implementing fault detection systems. Baseline data provides objective measurement criteria for evaluating program success and ROI calculation.
Effective baselines capture both direct costs (parts, labor, contractors) and indirect impacts (lost production, quality issues, safety incidents) associated with current maintenance approaches. This comprehensive baseline enables accurate ROI assessment and program justification.
Success metrics should align with organizational priorities while providing clear program evaluation criteria. Common success metrics include maintenance cost reduction, downtime reduction, and maintenance work order completion rates.
Leading organizations establish metrics that balance maintenance efficiency (cost reduction, labor productivity) with reliability outcomes (equipment availability, failure prevention). This balanced approach ensures programs deliver sustainable value rather than short-term cost reduction at the expense of long-term reliability.
Scaling Across Facilities
Phased rollout approach enables organizations to apply lessons learned from pilot programs while building internal capabilities and stakeholder confidence. Successful scaling typically follows a geographic or asset-class progression that leverages existing expertise.
Multi-site organizations often implement fault detection systems facility by facility, allowing local maintenance teams to develop expertise before supporting additional locations. Single-site operations may scale by asset type or criticality level.
Change management requirements include training programs, workflow modifications, and performance measurement adjustments needed to support new fault detection capabilities. However, successful implementation requires buy-in from maintenance technicians, operations personnel, and management teams.
Research firms such as McKinsey report that the majority of digital transformations fail to meet their objectives. This is most often due to change management issues rather than technical problems. Successful programs invest implementation effort in training, communication, and change management activities.
Training requirements encompass both technical skills (sensor installation, data interpretation) and workflow changes (work order processes, communication protocols). Training programs should address different skill levels and job functions affected by new fault detection capabilities.
Integration planning ensures fault detection systems work effectively with existing maintenance management systems, operational procedures, and organizational structures. Integration planning identifies interface requirements, data flow needs, and workflow modifications needed for successful implementation.
Best Practices from Industry Leaders
Lessons from Spotlight Award winners demonstrate proven approaches for successful fault detection implementation across diverse industrial environments. Award-winning programs typically share common characteristics: strong leadership support, clear success metrics, and systematic implementation approaches.
Strong leadership support creates the conditions for success. At Atlas Energy Solutions, an industrial sand producer in Monahans, Texas, management empowered reliability engineer Richard Calhoun with the autonomy to own the program fully. He earned his CAT I vibration certification, learned to maintain sensors, and taught supervisors to understand and trust what the data was telling them. The program grew because leadership built the workflows and accountability around one person who believed in it. As Richard puts it, “This isn’t just about maintaining equipment. It’s about constantly improving how we work and driving excellence across everything we do.”
Clear success metrics keep teams focused and build organizational credibility. At Frito-Lay’s Taber facility in Alberta, the team tracks downtime prevented as their primary measure because it’s the number that resonates with operations and tells a clear story to leadership. They document every win, building an evidence base that converts skeptics and justifies continued investment. The program also proved resilient through staff changes because the data keeps working regardless of who is on shift. As maintenance specialist Duncan Waldie noted, “Augury continues capturing information even when we have staffing changes or other disruptions. That consistency keeps our program running strong no matter what.”
Systematic implementation turns early wins into lasting programs. The maintenance team at Dairy Farmers of America’s Middlebury Center in Pennsylvania started with their hardest problem: a dryer intake fan that had failed repeatedly and resisted every fix. When they finally resolved it using vibration data, and could see in real time that the repair had actually worked, the program earned credibility across the facility. Regular planning meetings between production and maintenance replaced midnight emergency calls. Corporate leadership now points to Middlebury Center as the model for the broader DFA network. Plant Manager Jeff Bacon describes the shift simply: “We get to do a lot more planning ahead of time instead of planning after something fails. That’s been the huge win, coordinating between production and maintenance before equipment actually breaks.”
Common pitfalls to avoid include an overly ambitious initial scope, insufficient training investment, and inadequate integration with existing workflows. Successful programs start with a manageable scope and expand based on demonstrated value and organizational capability.
Technology-focused implementations often struggle when they neglect the people and process changes required for success. Sustainable programs balance technology deployment with appropriate change management and capability development.
Ready to start your pilot program?
Schedule a consultation with our experts
Connection to Predictive Maintenance
Fault detection and isolation provide the foundational data and insights that enable effective predictive maintenance strategies. While often used interchangeably, these approaches serve complementary roles in comprehensive reliability programs.
Predictive maintenance uses historical patterns, operational data, and statistical models to forecast when equipment failures are likely to occur. This forward-looking approach enables maintenance scheduling optimization and long-term asset planning. McKinsey research found that predictive maintenance can decrease maintenance costs by 10% to 40% compared to single-approach programs.
Fault detection and diagnostics focuses on identifying current abnormal conditions that indicate developing problems. Detection systems provide real-time awareness of equipment health changes that affect immediate operational decisions.
The most effective maintenance programs combine both approaches: fault detection provides immediate awareness of developing problems while predictive analytics forecast optimal intervention timing based on equipment condition trends and operational factors.
Industry context and trends indicate increasing integration of fault detection with broader Industry 4.0 initiatives, including digital twins, artificial intelligence, and autonomous maintenance systems. These integrations enable more sophisticated predictive capabilities while maintaining the immediate awareness that fault detection provides.The bigger picture of reliability encompasses asset management strategies that optimize equipment lifecycle value through appropriate application of preventive, predictive, and proactive maintenance approaches. Fault detection provides the operational intelligence needed to make optimal maintenance decisions across diverse asset portfolios.
Resources and Further Learning
Technical Deep Dives
- 10 Common Machine Fault Types Detected by Machine Health
- Vibration analysis 101 webinar
- Vibration analysis 102 webinar
Industry Applications
Related Resources
- Advanced Manufacturing Toolset – On-demand reliability webinar series
- Machine Health for Dummies – Introductory guide to machine health monitoring concepts
- Vibration Institute Certification Programs – Professional development opportunities
- Forrester Total Economic Impact study
- McKinsey industrial operations insights
- Department of Energy Advanced Manufacturing Office
Take the Next Step in Equipment Reliability
Ready to transform your maintenance operations from reactive to proactive? Augury’s Machine Health solutions combine advanced fault detection and isolation capabilities to provide the reliable insights your maintenance team needs.
Plus, every single alert is verified by a vibration analyst, ensuring that each alarm is evaluated by urgency, timeliness, and a supporting Augury account team to answer any questions or advise on best steps.
Discover how industry leaders like DuPont achieve 7x ROI through predictive maintenance technologies that catch asset faults before they impact production capacity.
Get a Demo to see how Phase Analysis and comprehensive fault detection can increase uptime, reduce maintenance costs, and support more reliable operations at your facility.
Frequently Asked Questions
How accurate is fault detection for diagnosing industrial machine faults?
Fault detection accuracy depends on the sophistication of analysis methods and the quality of training data. Modern systems like Augury’s Machine Health achieve high accuracy by leveraging an expansive machine database and insights powered by more than 10 years of machine monitoring.
What specific machine faults can fault detection systems identify?
Comprehensive fault detection systems identify bearing wear, shaft misalignment, rotating asset imbalance, coupling problems, mechanical looseness, resonance conditions, cavitation, and belt deterioration, among other common failure modes.
How do I choose the right fault detection system for my facility?
Start with a pilot program covering 3-5 critical assets with documented failure history and clear business impact. Select systems that integrate with existing maintenance management infrastructure while providing appropriate detection capabilities for your asset types and operating conditions.
How does Phase Analysis improve the accuracy of fault detection and diagnostics?
Phase Analysis compares the phase relationships between multiple vibration signals to eliminate diagnostic ambiguity. It moves diagnostics from “it’s one of these two problems” to “it is exactly this problem” by distinguishing between faults that might generate similar frequency signatures but different phase patterns. This capability helps pinpoint exact fault origins, differentiate mechanical vs. electrical issues, and validate AI findings with signal-level evidence.





